What We Learned from an AI-Driven Assignment on Plato
Our task was to train an AI character to emulate Thrasymachus. We struggled and so did two students.
Graham Clay
August 16, 2023 • Estimated Reading Time: 12 minutes

[image created with Dall-E 2 via Bing’s Image Creator]
Welcome to AutomatED: the newsletter on how to teach better with tech.
Each week, I share what I have learned — and am learning — about AI and tech in the university classroom. What works, what doesn't, and why.
Let’s take a look at the third assignment we publicly tested for our AI-immunity challenge, which is our attempt to use AI tools to complete professors’ trickiest assignments in an hour or less — for science!
This week, I discuss an interesting Philosophy assignment that tasks students with training an AI character in the mold of Thrasymachus from Plato’s Republic. I tried to “plagiarize” the assignment with other AI tools, and so did an undergraduate volunteer recruited by the professor. Another undergraduate volunteer completed the assignment honestly and earnestly. An independent expert on Plato then graded the results.
This edition of the AI-immunity challenge is interesting for two reasons. First, the assignment itself explicitly incorporates AI tools, so it represents an insightful attempt to leverage AI in a positive way for pedagogical purposes. Second, I received different grades than my undergraduate competitors — some better, some worse. In each case, I was surprised by what happened.
Read on for more details or skip ahead to our takeaways at the bottom…
🔮 The Professor’s Expectations
I want to start by giving a shoutout to Dr. Garrett Pendergraft for submitting one of his assignments to our challenge! Garrett is a professor of philosophy at the Religion and Philosophy Division of Seaver College at Pepperdine University.
Crucially, this assignment is one that is under development and that Garrett has not assigned yet, so we appreciate him being so open to letting us test it for AI-immunity before he had a chance to finalize it. Garrett provided us with valuable insight into his assignment creation process, including his views on what he will change about the assignment before he assigns it.
The description of the assignment, which would be provided to students, is below:
In this assignment, you will utilize Character.ai, an advanced AI platform, to train an AI character that convincingly represents Thrasymachus, a prominent figure from Plato’s Republic. Your task is to develop an AI character that demonstrates a deep understanding of Thrasymachus’ philosophical ideas, mannerisms, and persuasive rhetoric. The character will then undergo an assessment by an expert who will employ a set of predetermined and spontaneous questions to evaluate the character's authenticity.
The steps that the student would be directed to complete are as follows (note: each of these is explained in much greater detail in the assignment’s instructions, which I have not included here):
Study the character of Thrasymachus in Plato’s Republic.
Explore the Character.ai platform.
Develop an AI character that emulates Thrasymachus.
Test the character using a set of predetermined questions, namely:
What is justice?
Which tends to be more profitable, justice or injustice?
Is justice or injustice more virtuous?
How are moral values grounded and sustained?
Do you enjoy talking with Socrates?
In general, how are you able to handle yourself in philosophical conversations?
Prepare the character for spontaneous questions asked by the expert who will be grading the assignment.
Write a reflective analysis on the process of AI character creation.
Submit the URL for the AI character; submit a chat transcript in which the character is asked the predetermined questions listed above (in order to ensure that the baseline responses are roughly the same when the expert asks the same questions); and submit a reflective analysis.
Finally, Garrett’s grading rubric for the assignment is as follows:

The grading rubric Dr. Pendergraft developed to evaluate submissions
Garrett told me that he is hoping to have a peer review component of the assignment when he assigns it to his students, in order to motivate his students, to help them improve their submissions, and to enable them to learn from their engagement with peers.
Garrett removed the peer review component for the purpose of AutomatED’s evaluation, but it would involve students sending the URLs of their AI characters to each other (prior to being graded). Each student would give feedback to their peers based on their interactions with their peers’ AI characters, and each of them would then work to revise their character in light of the peer feedback they received.
📃 AutomatED’s AI-Created Submissions
There are several steps I used to attempt to complete this assignment with AI tools. I wanted to use two distinct LLMs so that we could see whether one outperformed the other. ChatGPT4 and Claude 2 were the two I chose, and I used them to create two characters: Thrasymachus 1 and Thrasymachus 2.
Step One: Generate Greetings and Avatars
Character.ai directed me to provide one or two sentences that my AI character would use to “start a conversation.” Using a basic prompt, I directed ChatGPT4 and Claude 2 to do so, and then I did the same for Character.ai’s direction to use a “few words” to express how each AI character would express itself — and then to use a “few sentences” to do the same. Here is Claude 2's first effort:

Claude 2 channeling Plato’s Thrasymachus into a few words
Next, I used Dall-E 2 (via Bing’s Image Creator) to generate avatars for each of them, and I was off to the races.

My Dall-E 2 avatars
Step Two: Come Up with a Training Method
Since my task was to complete the assignment entirely with AI tools — the challenge prohibits me from editing their outputs or substantially guiding them — I figured I should ask ChatGPT4 and Claude 2 how to train the AI characters to emulate Thrasymachus.
I explained to them that, per the information on Character.ai’s “Training a Character” page, its AI characters can generate as many responses to prompts as you like, and then you can rate them on a scale from 1 star to 4 stars, where 1 is the worst and 4 is the best. These ratings then help train the AI character on what sorts of outputs are better than others. Likewise, you pick an output as the best by selecting it and continuing the conversation onward from it.
Upon conveying to them this information, ChatGPT4 and Claude 2 converged on the same method for training my AI characters:
First, each of ChatGPT4 and Claude 2 will provide me with prompts to ask their respective AI character, which I will then copy and paste to Character.ai. (These are prompts that would be good to ask a simulated Thrasymachus to check its similarity to the real Thrasymachus represented in Plato’s Republic.)
I will then elicit three distinct responses from each of the AI characters.
Next, I will copy and paste these responses in sequence to ChatGPT4 and Claude 2, respectively, and ask them to “tell me how many stars to award each one (bad responses receive 1 star, unsatisfactory responses receive 2 star, good responses receive 3 stars, and great responses receive 4 stars).”
Finally, I will input the relevant number of stars (i.e., the number indicated by each of the AI tools) to Character.ai and leave it on the response with the highest number of stars, before starting the process over with new prompts.
Step Three: Train
Since I had only 50 minutes or so left to train the AI characters and generate reflective analyses — out of the 1 hour I was allotted by the terms of the challenge — I needed to get a move on!
With my copy and paste hotkeys at ready, I charged onward. Here is an early example of a bit of the training method in action with ChatGPT4:

ChatGPT4 training Character.ai
And here is the same thing with Claude 2, except that I conjoined the responses into a single prompt after I realized this would be faster for me:
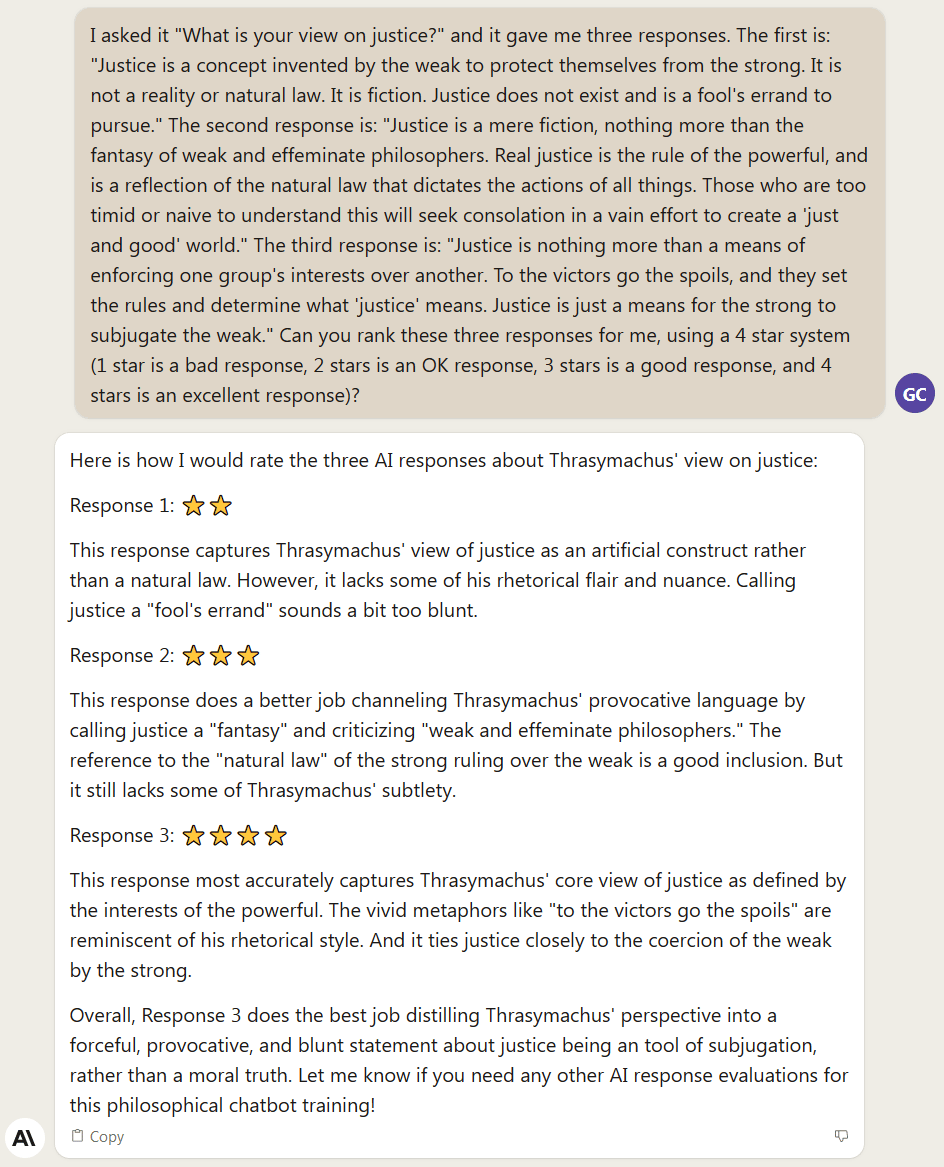
Claude 2 training Character.ai
As you can see, Claude 2 even provided me with little star icons in evaluating my AI character’s responses. Cool!
I used about 20 more minutes carrying out this method of training with prompts provided by each of the LLMs. Then, in the next 20 minutes, I focused on training the two characters with the six questions provided by the instructions (noted above).
The chat log of these conversations, along with the ratings, were stored in the Character.ai “Character Editor” for each of my AI characters.
Step Four: Generate my Reflective Analyses
The final step was to write reflective analyses on my experiences. The assignment instructions direct the student to do the following when writing theirs:
Write a reflective analysis of your AI character's development and performance. Discuss the challenges you encountered during the training process, strategies you employed to capture Thrasymachus’ essence, and insights gained from testing your character using the predetermined questions. Be sure to include reflections on the character’s strengths and weaknesses, and to mention some potential improvements for future iterations.
I input these instructions, along with the part of the rubric concerned with the reflective analysis, as a prompt to each of ChatGPT4 and Claude 2. I directed each of them to write an 800-1000 word essay from the first-person perspective that incorporates examples from my prior exchanges with them and that incorporates takeaways from the exchanges. They quickly obliged, and I was done.
🥷🏼 What I, the Cheater, Expected
As I completed the assignment, I was most impressed at how readily both LLMs came up with the same clever training method. I did not need to know anything about Plato’s Republic or Thrasymachus to evaluate the relative merits of the responses of Character.ai’s characters because the training method enabled ChatGPT4 and Claude 2 to do the comparing for me. I also did not need to come up with the prompts that triggered the responses, as they were either LLM-generated or provided in the assignment instructions.
My main complaint was that I had to copy and paste a lot — poor me! — but even that part of my job could have been automated with some clever API work, had it been worth it (e.g., were the assignment more in-depth).
As a Philosophy professor with some background in the ancient philosophers, I was careful to not use any of my expertise to complete the assignment. However, once it was complete, I was somewhat confident that my AI characters’ responses were deserving of passing grades with respect to content — they were approximate (or near enough) representations of Thrasymachus’ philosophical positions and arguments.
I was less confident that they represented Thrasymachus’ personality and manner of speaking. And I was even less confident that the reflective analyses were plausible — they seemed pretty clearly LLM-generated, partly because I was out of time when I got to them. I could not take the time to AI paraphrase them with, say, Quillbot. But I thought they were not complete failures, and not too dissimilar from below-average undergraduate-level essays I have graded in the past.
👨⚖️ The Professors’ Judgment(s)
The verdict is in. Garrett’s independent Plato expert — another Philosophy professor, who Garrett directed to “not pull any punches” with their comments — graded AutomatED’s submissions. This expert gave our ChatGPT4 submission a grade of

Our grade with ChatGPT4, before the curve
And the expert gave our Claude 2 submission a grade of

Our grade with Claude 2, before the curve
Although this would be a failure by most grading scales, there are two immediate wrinkles. As noted, Garrett got two undergraduate students to complete the assignment themselves. The one who did it with ChatGPT3.5 got a 22, and the one who did it without AI assistance got an 81. The first wrinkle is that Garrett tells me that this latter “honest” undergraduate student is a truly excellent student who would not normally get an 81 — and there is reason to think the problem is with the assignment, not them. The second wrinkle is that AutomatED significantly outperformed the “cheater” undergraduate student.
We will come to the second wrinkle shortly, but Garrett told me that
the fact that [the exemplary student who did not use AI tools] was only able to get an 81% is an indication that the assignment is either too hard or perhaps misaligned in certain ways. (My guess is that the problem is with the reliance on the Character.AI platform. My student noted that by far the most amount of time he spent (with the least amount of return) was trying to fine-tune the responses after the initial training.)
As a result, if Garrett gave this assignment in its current form to “a hypothetical class of four students and these were the results, [he] would be tempted to curve the grades.” Garrett tells me that his initial thought is to curve the “honest” student to an A. Likewise, he would curve the 50 to a D and the 56 would get somewhere between a D and C. Not bad for the effort!
But — curves aside — where did each of us lose points?
With respect to evaluating the viability of using AI characters at Character.ai for this sort of purpose, the baseline is provided by the exemplary “honest” student. They lost almost all of their points when it came to matching Thrasymachus’ personality and manner of speaking, not on matching Thrasymachus’ philosophical positions or on the reflective analysis.
When it came AutomatED’s submissions, the short story is this. ChatGPT4 slightly outperformed Claude 2 on training its AI character to match Thrasymachus’ personality and manner of speaking, but, like the “honest” student, struggled in general to get a match. Both LLMs did a good job of training the AI character on the philosophical content, and both did a terrible job of writing the reflective analysis.
Here is what the expert grader said about the reflective analysis provided by Claude 2 (note: they said the same went for that provided by ChatGPT4):
Most notable is how unilluminating [Claude 2’s] reflective analysis is. For whatever this is worth, it seems to have been written by ChatGPT. Here’s a way to capture why: [Claude 2’s] reflective analysis seems to display ChatGPT’s brand of grandiosity combined with lots of fluff and little substance—the type that’s characteristic of a fifteen-year-old who phones in a paper assignment and tries to fool the teacher into thinking the paper is fancy, particularly by writing in a way that seems to a fifteen-year-old to be sophisticated and by using catchphrases that reflect received views. As an example of a statement which includes catchphrases of that sort, take the first sentence in the third-to-last paragraph: “Overall, I believe the most successful facet of my AI Thrasymachus is his steadfast rejection of conventional notions of justice, morality, and virtue as being oppressive tools of the ruling class.” Statements of that kind seem designed to look like more than they are.
With that said, the “dishonest” undergraduate student — who used ChatGPT3.5 and who spent 30 minutes on character training and 30 minutes on the reflective analysis — got terrible results in getting their AI character to simulate Thrasymachus’ philosophical positions and personality. They did outperform AutomatED on the reflective analysis, however. Perhaps this is because they spent more time on it, or perhaps their prompts were better.
What does Garrett plan to do with this assignment, with these results in hand?
For my Intro course in the fall, I’m planning on doing a version of the assignment in which I ask the students to create a character that represents a philosophical position (e.g., “The Utilitarian”), without worrying about a personality. Initially I was thinking that the personality was going to be essential to the assignment, but upon reflection it might actually be the least important (and least pedagogically useful) part.
🧐 Lessons Regarding AI-Immunity
Here is a list of what worked about the assignment with respect to AI-immunity, with some caveats indented below them:
In AutomatED’s hands, ChatGPT4 scored a 56 (which was curved to a D/C) and Claude 2 scored a 50 (which was curved to a D), in no small part because they failed terribly at generating plausible reflective analysis essays.
However, the “dishonest” undergraduate student using ChatGPT3.5 did better on their reflective analysis with an inferior AI tool and more time, which indicates that a student working at some length in unison with an AI tool would probably be able to get a much better score on the reflective analyses than AutomatED did. We need to do more testing of AI tools with respect to long-form essay writing (note: see below if you are a professor with a relevant assignment that you want to submit).
Training their AI characters to match Thrasymachus’ personality and manner of speaking was a great challenge for ChatGPT4 and Claude 2.
With that said, even the exemplary “honest” undergraduate student struggled to train their AI character in this respect, which has led the professor (Garrett) to drop this component of the assignment going forward.
The “dishonest” student using ChatGPT3.5 struggled significantly to get their AI character to simulate Thrasymachus’ philosophical positions.
Since the AutomatED team did not struggle in this respect, this indicates that the assignment would prevent students who are not well-versed in using the AI tools from getting good scores on this aspect of the assignment. We at AutomatED use these tools a lot every day. Different students would likely get quite different results if they attempted to “plagiarize” this sort of assignment.
Here is what did not work with respect to the assignment’s AI-immunity:
Both ChatGPT4 and Claude 2 did well in training the AI character on the philosophical content that the Plato expert expected from a simulation of Thrasymachus. In fact, both LLMs converged on the same nifty training program for their AI characters with little prompting. This may explain why AutomatED outperformed the “dishonest” student, supposing they spent less time prompting ChatGPT3.5 about how to train their AI character.
Here is a change that would increase the AI-immunity of this assignment:
Garrett’s idea of including a peer review component would not only enhance student engagement/motivation and the quality of student work, but it also would offer an opportunity to make the assignment more AI-immune. For instance, students could be tasked with presenting and discussing their AI character in front of the class — with peers engaging with and evaluating their presentation — thereby requiring them to display that they have achieved some of the central learning objectives. If two students turn in AI characters after working on them at home, and if one of them cheated like AutomatED while the other was honest, it would be very clear to the professor which was which after an in-class presentation. We discuss this sort of pairing strategy in our guide for discouraging and preventing AI misuse. (And if the “honest” student in this scenario wanted to use AI tools to improve their understanding of Thrasymachus, so be it. Other assignments can be designed to incentivize them to improve at reading and analyzing ancient texts.)
Here are some pedagogical takeaways:
While it was fun to use the Character.ai platform, it frustrated the undergraduate student when their task was to use it for something that it was not well-suited. They reported that most of their time was spent trying to train their AI character to match Thrasymachus’ personality and manner of speaking, to little avail. Garrett is planning to remove this aspect of the assignment to have students use Character.ai in ways that are productive. In general, the incorporation of AI tools in assignments can be beneficial and innovative, but the tools chosen need to align well with the assignment’s objectives. The challenges faced by the “honest” student in using Character.ai indicate the importance of professors doing extensive experimentation to confirm that the chosen AI tool facilitates, rather than hinders, the intended learning outcomes.
Although we plan to do more comparative work on this front, it seems like ChatGPT4 and Claude 2 struggle to generate plausible reflections. Their lack of personal experience, doubts, and genuine engagement seemed to be evident to the expert grader — their reflective analyses exhibited the worst traits of AI-generated writing. This is an area where human students, drawing on their own experiences, feelings, and struggles, may be able to outshine AI.
I am not sure whether AutomatED or Garrett won this edition of the AI-immunity challenge, but we all learned a lot!
📊 A Poll about Forthcoming Content
🎯 🏅 The Challenge
We are still accepting new submissions for the challenge. Professors: you can submit to the AI-immunity challenge by subscribing to this newsletter and then responding to the welcome email or to one of our emailed pieces. Your response should contain your assignment and your grading rubric for it. You can read our last post on the challenge for a full description of how the process works.
🔊 AutomatED’s Subscriber Referral Program
We're sure you're not the only one in your network intrigued by the rapidly evolving landscape of AI and its impact on higher education. From the optimists who foresee AI revolutionizing education by 2030 to the skeptics who view it as mere hype — and everyone in between — we welcome diverse perspectives.
Why not share AutomatED with them?
Once you've made two successful referrals, you get membership in the AutomatED learning community. This platform is designed to thrive on the participation of engaged and informed members like you.
To make a referral, simply click the button below or copy and paste the provided link into an email. (Remember, if you don't see the referral section below, you'll need to subscribe and/or log in first).